Machine Learning: Introduction,Types, Algorithms, and Real-World Applications.
- shravanibotta
- May 22, 2025
- 8 min read

What is Machine Learning and Why It Matters?
Machine Learning (ML) is a powerful subset of Artificial Intelligence (AI) that lies at the core of today’s technological transformation. It enables systems to learn from data, recognize patterns, and make informed decisions with minimal human intervention, without being explicitly programmed for each task.
As shown in the above Venn diagram, ML is part of a broader AI ecosystem, which also includes Deep Learning—an advanced technique inspired by the neural networks of the human brain, and Generative AI, which pushes boundaries by creating entirely new content such as images, text, music, and more.
ML touches our daily lives in countless ways: from recommending movies on streaming platforms, filtering spam in emails, and recognizing faces and voices on smartphones, to powering navigation tools, fraud detection systems, and diagnostic tools in healthcare.
Its significance lies not only in automating routine tasks but also in generating actionable insights from large datasets, enabling smarter decisions and driving innovation across industries.

Machine Learning can be broadly classified into two main categories: Supervised and Unsupervised Learning, each with distinct goals and approaches.
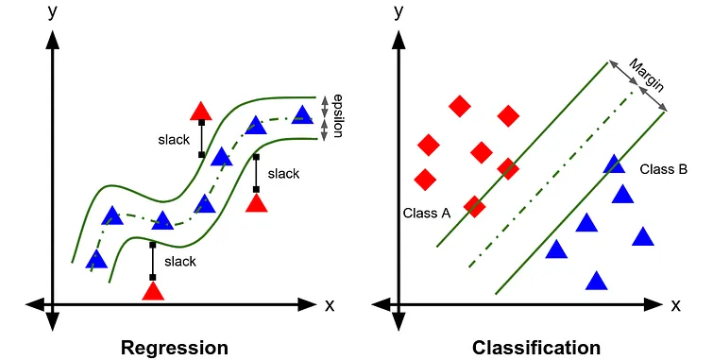
In Supervised Learning, the algorithm is trained on labeled data, meaning the input comes with corresponding output. This category is further divided into Classification and Regression tasks. The type of algorithm selected for an application depends on the underlying data such as Image, Text, Numerical, Voice and the sub category depends on whether the data is continuous or categorical.
Classification algorithms — such as Logistic Regression, Naive Bayes, K-Nearest Neighbors, Support Vector Machines, Decision Trees, Random Forest, Gradient Boosting, and Neural Networks are used when the output is a discrete label. For example, email spam detection, disease diagnosis, and credit card fraud detection.
Evaluation metrics for classification include accuracy, precision, recall, F1-score, and the confusion matrix.
Regression algorithms — including Linear, Polynomial, Lasso, Ridge, and the same classifiers adapted for continuous output—are used when the output is a continuous value, like predicting house prices, weather forecasting, or stock market trends.
Key evaluation metrics for regression include Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and R² score.
Brief Explanation Of Various Supervised Algorithms
1. Linear Regression
Linear Regression is one of the most fundamental and widely used algorithms for predictive modeling. It establishes a linear relationship between a dependent variable and one or more independent variables by fitting a straight line (called the regression line) that minimizes the difference between actual and predicted values. It's commonly used in scenarios such as predicting sales revenue, housing prices, or exam scores based on historical data.
2. Polynomial Regression
Polynomial Regression is an extension of linear regression where the relationship between the independent variable and the dependent variable is modeled as an nth-degree polynomial. This allows for capturing more complex, curved relationships in data that linear regression cannot handle. It's often used in scenarios like modeling population growth, price trends, or risk factors over time where non-linear trends are evident.
3. Lasso and Ridge Regression
Lasso (Least Absolute Shrinkage and Selection Operator) and Ridge Regression are regularized versions of linear regression used to prevent overfitting by adding a penalty term to the loss function. Ridge Regression uses L2 regularization to shrink coefficients toward zero without eliminating any, while Lasso uses L1 regularization which can reduce some coefficients to exactly zero, effectively performing feature selection. These are especially helpful in high-dimensional datasets like genomic data or marketing analytics.
4. Logistic Regression
Despite its name, Logistic Regression is used for classification tasks rather than regression. It predicts the probability of a binary outcome (e.g., yes/no, 0/1) using the logistic (sigmoid) function to map values between 0 and 1. It is widely used for tasks like spam detection, disease diagnosis, and customer churn prediction due to its simplicity and interpretability.
5. Naive Bayes Classifier Algorithm
The Naive Bayes algorithm is a probabilistic classifier based on Bayes’ Theorem, assuming independence between predictors. Despite its “naive” assumption, it performs remarkably well in many real-world applications like document classification, sentiment analysis, and spam filtering. It's fast, simple, and effective, especially with large text-based datasets.
6. Gradient Boosting Algorithms
Gradient Boosting is an ensemble technique that builds models sequentially, with each new model trying to correct the errors of the previous ones. Popular implementations like XGBoost, LightGBM, and CatBoost are known for their high performance and speed. These models are effective for structured/tabular data and are widely used in fraud detection, customer segmentation, and competitive machine learning challenges.
7. K-Nearest Neighbors (KNN) Classifier and Regressor
KNN is a simple, non-parametric algorithm that classifies or predicts outcomes based on the majority (for classification) or average (for regression) of the 'k' nearest data points in the feature space. It doesn’t require a training phase, making it straightforward but computationally intensive for large datasets. KNN is often used in recommendation systems, handwriting recognition, and anomaly detection.
8. Support Vector Classifier & Regressor (SVM & SVR)
Support Vector Machines (SVM) are powerful algorithms that aim to find the optimal hyperplane that separates data points of different classes with the maximum margin. For regression (SVR), it tries to fit the best line within a predefined margin of tolerance. These models are effective for both linear and non-linear problems using kernel tricks and are used in image classification, stock price prediction, and bioinformatics.
9. Decision Tree Classifier & Regressor
Decision Trees work by recursively splitting the dataset based on feature values to form a tree-like model of decisions. For classification, the leaves represent class labels, while for regression, they represent continuous output values. They are intuitive, easy to interpret, and are used in applications such as medical diagnosis, loan approval systems, and business decision modeling.
10. Random Forest Classifier & Regressor
Random Forest is an ensemble method that builds multiple decision trees and aggregates their outputs for more accurate and robust predictions. It reduces overfitting commonly seen in individual trees and is effective for both classification and regression tasks. Random forests are used in a variety of fields, including credit scoring, image classification, and predictive maintenance.
11. Neural Networks for Classification & Regression
Neural Networks are inspired by the human brain and consist of layers of interconnected nodes (neurons). They can model complex, non-linear relationships in data and are highly flexible. For classification tasks, they output class probabilities, while for regression, they produce continuous values. Neural networks power advanced applications like facial recognition, autonomous driving, speech recognition, and financial forecasting.










In contrast, Unsupervised Learning deals with unlabeled data, aiming to uncover hidden patterns without prior knowledge of outcomes.
It is divided into three major subtypes: Clustering, Transformations (Dimensionality Reduction), and Association.
Clustering algorithms like K-Means, Agglomerative Clustering, DBSCAN, and Gaussian Mixture Models group data points based on similarity. These are widely used in customer segmentation, social network analysis, and image compression. Evaluation for clustering models often uses Silhouette Score, Davies-Bouldin Index, and inertia (for K-Means).
Transformations such as PCA (Principal Component Analysis), NMF (Non-negative Matrix Factorization), and T-SNE are used to reduce data dimensionality while retaining meaningful structure, often applied in data visualization, gene expression analysis, and noise reduction. Although these models are not directly evaluated using accuracy, metrics like explained variance ratio and reconstruction error help assess performance.
Association algorithms—including Apriori, FP-Growth, and Eclat are used to discover interesting relationships or rules between variables in large datasets, commonly applied in market basket analysis (e.g., "people who bought X also bought Y"). These are evaluated using support, confidence, and lift metrics.
Brief Explanation Of Various Unsupervised Algorithms
1. K-Means Clustering
K-Means is a popular clustering algorithm that partitions data into k distinct groups based on feature similarity. It works by initializing centroids and iteratively assigning each data point to the nearest centroid, then updating the centroids until convergence. It's efficient and widely used in market segmentation, image compression, and customer behavior analysis. However, it assumes spherical clusters and requires the number of clusters to be predefined.

2. Agglomerative Clustering
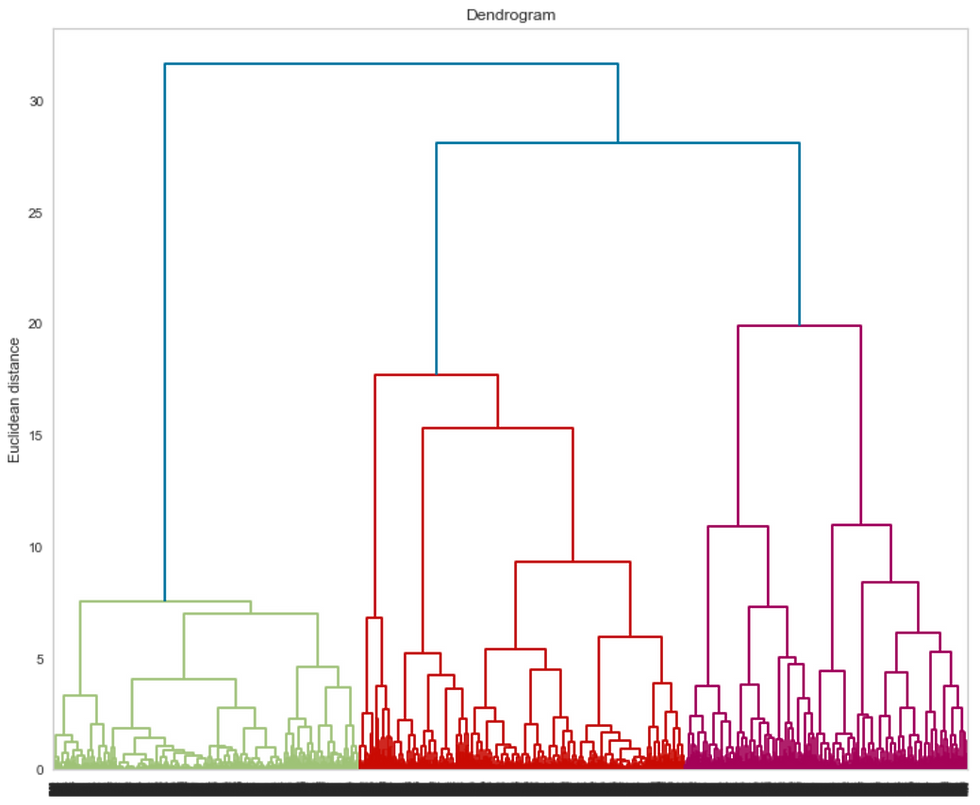
Agglomerative Clustering is a hierarchical clustering technique that builds clusters by progressively merging the closest pair of clusters until all points are grouped into a single cluster or a stopping criterion is met. It produces a dendrogram a tree-like diagram representing nested clusters. This method is useful when the structure of data is unknown and is commonly applied in gene expression analysis, document clustering, and social network analysis.
3. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN groups together data points that are closely packed (high-density areas) while marking points in low-density regions as outliers. Unlike K-Means, it doesn’t require the number of clusters to be specified and can identify clusters of arbitrary shapes. It's ideal for spatial data analysis, anomaly detection, and applications like identifying hotspots in geolocation data.

4. Gaussian Mixture Models (GMMs)
Gaussian Mixture Models assume that the data is generated from a mixture of several Gaussian distributions. Unlike K-Means which assigns each point to one cluster, GMMs provide probabilities of belonging to each cluster, offering soft clustering. GMMs are especially useful in scenarios involving overlapping clusters such as speaker recognition, image segmentation, and financial modeling.

5. PCA (Principal Component Analysis)
PCA is a dimensionality reduction technique that transforms high-dimensional data into a lower-dimensional form by identifying directions (principal components) that maximize variance. It helps reduce noise and redundancy while preserving essential structure. PCA is widely used in preprocessing for visualization, speeding up algorithms, and applications like facial recognition and genetics.

6. NMF (Non-negative Matrix Factorization)
NMF is a dimensionality reduction technique that factorizes a non-negative matrix into two lower-rank non-negative matrices, making it well-suited for interpretability. It’s particularly useful when data is inherently non-negative (e.g., pixel intensities, word counts). Applications include topic modeling, document clustering, and image processing.

7. T-SNE (t-distributed Stochastic Neighbor Embedding)
T-SNE is a nonlinear dimensionality reduction technique primarily used for visualizing high-dimensional data in two or three dimensions. It preserves local similarities between points, making patterns and clusters easier to interpret visually. T-SNE is commonly used in exploratory data analysis, such as visualizing word embeddings or genomic data.

8. Apriori
Apriori is an association rule learning algorithm that identifies frequent itemsets in large datasets and derives rules for predicting item associations. It operates on the principle that subsets of frequent itemsets must also be frequent. It also follows horizontal database layout and employs breadth-first search approach. Apriori algorithm is widely used in market basket analysis to discover product purchase patterns like customers who buy bread also tend to buy butter.

9. FP-Growth (Frequent Pattern Growth)
FP-Growth is an efficient alternative to Apriori that avoids generating candidate itemsets. Instead, it constructs a compact data structure called an FP-tree and mines frequent itemsets directly. It significantly reduces computation time and is ideal for large datasets. FP-Growth is used in recommendation engines, sales pattern analysis, and retail analytics.

10. Eclat (Equivalence Class Clustering and bottom-up Lattice Traversal)
Eclat (Vertical Apriori) is another algorithm for mining frequent itemsets, using a vertical data format using depth-first search (DFS) unlike the apriori's BFS. It is faster and more memory-efficient for dense datasets compared to Apriori. Eclat is used in domains like telecommunications, e-commerce, and web usage mining to uncover item co-occurrence patterns.

Conclusion
Machine learning, with its diverse types and wide range of algorithms, provides a robust and adaptable toolkit for tackling real-world challenges across numerous domains. Whether it's diagnosing diseases in healthcare, detecting fraud in finance, personalizing shopping experiences in e-commerce, or optimizing routes in transportation, ML enables data-driven decision-making and intelligent automation. By understanding the strengths and applications of each algorithm, we can harness the full potential of machine learning to drive innovation and solve complex problems more effectively.
In addition to supervised and unsupervised learning, reinforcement learning, where models learn through trial and error by interacting with their environment is another powerful paradigm. It plays a vital role in areas such as robotics, game AI, and autonomous systems. While this blog focused on supervised and unsupervised learning, reinforcement learning will be explored in depth in future posts.
Books on machine Learning for Beginners or Self-Learners:
Introduction to Machine Learning with Python: A Guide for Data Scientists By Andreas C. Muller & Sarah Guido , Published By O'REILLY
Hands-On Machine Learning with Scikit-Learn and Tensorflow: Concepts, Tools, and Techniques to Build Intelligent Systems By Aurelien Geron, Published By O'REILLY
Online Resources: 1. Youtube channels - Serrano Academy
GeeksforGeeks
Medium