EDA using Pandas Profiling
- Ruchi Sharma

- Mar 31, 2022
- 3 min read
Updated: Apr 8, 2022

Photo by Stephen Phillips - Hostreviews.co.uk on Unsplash
EDA (Exploratory Data Analysis) :
Exploratory Data Analysis (EDA) is an approach for data analysis that employs a variety of techniques (mostly graphical) to
Maximize insight into a data set
Uncover underlying structure
Extract important variables
Detect outliers and anomalies
Test underlying assumptions
With the help of EDA, we can find out missing values, duplicated rows, no. of columns , no. of rows, shape of data, size of data, mean, median. In general various insights of data. For that we have to write more code. But with the help of Pandas library we can do that in easy way.
EDA using Pandas Profiling :
EDA can be automated with the help of pandas library caller Pandas Profiling . It is a great tool to create reports in the interactive HTML format which is quite easy to understand and analyze the data. Pandas_profiling extends the pandas DataFrame with df.profile_report() for quick data analysis. Lets explore Pandas Profiling in detail and see the benefit of this Magical single line of code.
Import Dataset :
Lets take a example of IPL Dataset :
import pandas as pd
df = pd.read_csv('ipl_data.csv')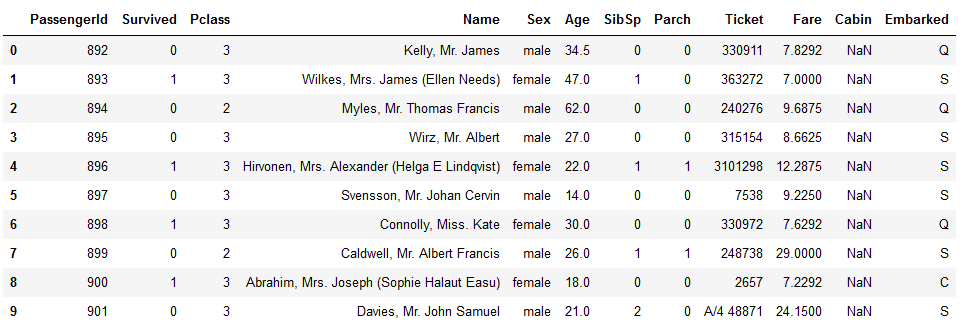
Installation of Pandas Profiling:
First step is to install using command:
! pip install pandas-profilingThen we generate the report using these commands:
from pandas_profiling import ProfileReport
prof = ProfileReport(df)
prof.to_file(output_file ='output.html')It will show progress like this

If you open "Ouput.html" it will give full details in following sections:
Overview
Variables
Interactions
Correlations
Missing Values
Sample
We will discuss each sections in details
Overview :
Overview provides statistics about Dataset like no. of variables (Columns) , no. of observations (Rows) , Missing cell (no. of cells = no. of row * no. of columns ), Duplicate cells , Total size in memory. Variable type (like Categorical, Numerical, Boolean) .

In Alerts/ Warning we can find warnings on variables (column) like which two columns are highly corelated , Which column has unique value, Constant value .

The reproduction tab simply displays information related to the report generation. It shows the start and ends the time of the analysis, the time taken to generate the report, the software version of pandas profiling, and a configuration download option.

Variables :
This section provides detail analysis on Variables/Columns/Features of the Dataset that totally depend on type of Variables/Columns/Features like Numeric, String , Boolean etc. .
Numeric variables :
For Numeric variable report provides details like distinct , missing value , mean , zeros , memory size. You also get distribution in Histogram graph.

If you want to know more details like Statistics, Histogram, Common values, Extreme values you can press on the Toggle details button.

String variables:
For string variables, you will get Distinct (unique) values, distinct percentage, missing, missing percentage, memory size, and a horizontal bar presentation of all the unique values with count presentation.

In toggle details you will find :

Boolean variables:
For boolean variables, you will get Distinct (unique) values, distinct percentage, missing, missing percentage, false and true.

In toggle details you will find:

Interaction :
Interaction sections gives more details with bivariate analysis/multivariate analysis .

Correlations :
Correlation is a statistical measure that expresses the extent to which two variables are linearly related (meaning they change together at a constant rate). It’s a common tool for describing simple relationships without making a statement about cause and effect. In the pandas profiling report, we have 5 types of correlation coefficients: Pearson’s r, Spearman’s ρ, Kendall’s τ, Phik (φk), and Cramer's V (φc).

Missing values:
This report also gives detail analysis of Missing values in the four types of graph Count, matrix, Heatmap and dendrogram.


Sample:
This section displays the first and last 10 rows of the dataset.

Pandas profiling disadvantage :
The main disadvantage of pandas profiling is its use with large datasets. With the increase in the size of the data the time to generate the report also increases a lot.
One way to solve this problem is to generate the report from only a part of all the data we have.
An example with code:
from pandas_profiling import ProfileReport
prof = ProfileReport(df.sample(n=100)
prof.to_file(output_file ='output.html')