Attention Mechanisms: What They Are, How They Work, and Why They Matter
- ravula greeshma
- Jun 5
- 5 min read


Here's what actually sparked my interest in Attention Mechanisms
Back in 2021, I was working on a research study - "EEG Emotion recognition using DEAP dataset"
EEG (Electroencephalogram) - if you haven't heard of it, is basically a way to record electrical activity in your brain ,you wear a headset with electrodes, and it captures your brainwaves in real time. The DEAP dataset is a collection of EEG recordings from 32 participants who watched music videos, with their emotional responses rated across things like valence and arousal. So my research task was: Can a model look at someone's brainwaves and figure out what they were feeling?
I was trying to improve my model's accuracy for emotion recognition and somewhere in that process I stumbled onto a paper called Attention Is All You Need.
Honestly? I didn't fully get it at first read. But something about it stuck, and my immediate thought was ,okay I don't completely understand this yet, but why not just try it on my research study ? EEG is sequential data, and not every single timestep in a brainwave carries useful information. Some moments matter, most don't. And training on a dataset that large used to take hours. So if there was a smarter way to focus on what actually mattered in the signal, that felt worth chasing.
Fast forward to now in 2026, we're generating videos from text prompts, building apps through conversation, running teams of AI agents. The same idea underneath all of it. Wild to think about!
So what is attention, really?
Let me actually break down how attention works, because it's simpler than it sounds.
Read this paragraph slowly and notice what your brain does. You don't process every word with the same energy. Your eyes linger on the things that feel relevant. You skip over filler. Some phrases stick. Most don't.
That instinct i.e. the ability to selectively focus is something AI researchers spent years trying to teach machines. And when they finally figured out a mathematical way to do it, it completely transformed the field.
That idea is called an attention mechanism. It's the mechanism inside Chat GPT and the reason modern AI can handle paragraphs instead of just words.
First, what's the actual problem?
Say you're building a model to predict which customers are about to cancel their subscription. Your dataset has columns like Customer_ID, age, support tickets raised, monthly spend, and last login date.
Not all of these columns matter equally. A customer who filed 14 support tickets last month and hasn't logged in for 45 days gives a very different signal than someone who's been active and spending normally. Any good model needs to know what to focus on.
This same challenge shows up in every kind of sequential data. Text, speech, time-series sensor readings, EEG brain signals. Some parts of the sequence carry real signal. Most of it is noise. A model that treats every input equally is working against itself from the start.
The core insight Not all information deserves the same attention. Before attention mechanisms, most models didn't have a great way to act on this obvious truth.
How things were handled before : RNNs and LSTMs
For years, sequence problems were handled by Recurrent Neural Networks (RNNs) and their improved version, LSTMs. Here's the basic idea behind them:
Here's how an RNN processes a Sentence

The RNN reads one word at a time, updating a hidden state, a sort of rolling memory as it goes. By the time it reaches the end, theoretically, everything is captured in that final state. In practice?
Early information gets diluted. By step 200 in a long paragraph, what happened at step 5 is essentially gone. This is called the vanishing gradient problem. During training, the gradients that flow backward through the network shrink exponentially over long sequences, making it impossible to learn connections between distant words.

To solve this LSTMs were introduced where they added gating mechanisms like a little switches that decide what to remember and what to forget ,which helped. But they still had two serious problems:
The AI community needed something fundamentally different. Attention Mechanisms!!
What attention actually does?
Instead of compressing a whole sequence into a single state, an attention mechanism lets the model look at all positions simultaneously and decide, for each step, which other steps are most relevant.
Think about how you'd answer this question: "What does 'bank' mean in this sentence?"
You'd look at the surrounding words. If you see "river" nearby, it's probably the riverbank. If you see "mortgage," it's probably the financial kind. You're basically doing attention, weighting nearby words based on how relevant they are to answering your question.
Mathematically, attention works through three components:

A good way to think about this:
The Query is like a search term
The Keys are like indexed labels on every word and
The Values are the actual content you retrieve when there's a match. The better a word's Key matches your Query, the more of its Value gets included in the output.
The result is a set of attention weights , one number per position, all summing to 1. High weight means "pay attention here." Low weight means "this can be mostly ignored."
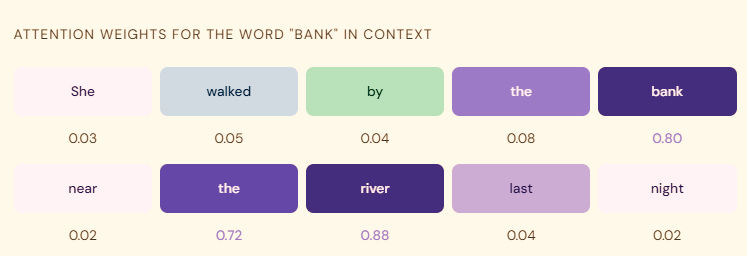
So that's the core idea. The model learns to look at the right things. And once you have that mechanism, you can do a lot with it — which is exactly what I ended up exploring in my research.
The shift in thinking Instead of asking "what did we see earlier?", attention asks "where in the input should I look right now?" That one change transformed what was possible.
What made me go deeper
Once I'd understood the basics, the obvious next question hit me: if attention is this powerful, do all attention mechanisms work the same way? Because there are many attention variants!
I genuinely didn't know. So In my research study, I tested five different variants of attention on top of Bidirectional LSTM for EEG emotion recognition: Soft attention, Self attention, Multi-head attention, Multilevel attention, and hard attention.
In the next post, I'll go deeper into each of those variants , what they actually do differently, what I found, and what it might mean for other sequential data beyond EEG.
Some variants that sounded more sophisticated on paper performed worse. One that seemed almost too simple outperformed models twice its complexity. That surprised me more than anything else.The lesson I walked away with wasn't really about EEG. It was about something more general: In machine learning, complexity doesn't automatically equal performance. And testing the obvious thing before reaching for the fancy one is almost always worth it.
References
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, "Attention is all you need," in Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017. [Online]. Available: https://arxiv.org/abs/1706.03762
Y. Kim and A. Choi, "EEG-based emotion classification using long short-term memory network with attention mechanism," Sensors, vol. 20, no. 23, p. 6727, 2020. [Online]. Available: https://doi.org/10.3390/s20236727
Koelstra, S., et al. (2012). DEAP: A Database for Emotion Analysis Using Physiological Signals. IEEE Transactions on Affective Computing, 3(1), 18–31. https://www.eecs.qmul.ac.uk/mmv/datasets/deap/
S. Chaudhari, V. Mithal, G. Polatkan, and R. Ramanath, "An attentive survey of attention models," ACM Transactions on Intelligent Systems and Technology (TIST), vol. 12, no. 5, pp. 1–32, 2021. [Online]. Available: https://arxiv.org/abs/1904.02874