Attention Mechanisms on EEG Data: What Actually Works
- ravula greeshma
- Jun 6
- 5 min read


Part one answered "what is attention - How they let a model focus on what matters in a sequence rather than treating everything equally. This post answers a harder question: Does it actually work?
I pulled attention mechanisms out of their comfort zone (text, language models, translation tasks) and dropped them into something messier: raw brain signals. The question was simple. Do these techniques actually hold up when the data isn't words in a sentence — but electrical activity measured across a human scalp?
Some variants worked beautifully. Few fell apart completely. Here's how it all unfolded.
A Few Prerequisites
What even is EEG?
EEG stands for electroencephalography. Small sensors placed on your scalp pick up the electrical signals your neurons produce when they fire. It's non-invasive, relatively affordable, and captures brain activity at millisecond resolution — which makes it well-suited for studying anything time-sensitive, like emotion.
The downside: EEG produces long, noisy sequences. Most of what you capture is background noise. A few moments in the recording carry the actual signal. If that sounds familiar — it should. That's exactly the type of problem attention was built to handle.

The DEAP Dataset
I used DEAP dataset - the standard benchmark for EEG emotion research. 32 healthy participants watched 40 1 min music videos while their brain signals were recorded. Afterwards, they rated their emotional state on two dimensions: valence (how positive or negative they felt) and arousal (how calm or excited). The task was to predict those ratings from the EEG signal alone.
We can Think of it as teaching a model to read the room — except the room is inside someone's head, and all you have are electrical fluctuations recorded from the outside.
The Baseline Model
Before testing any attention variant, I needed a reference point — something to beat. I used a Bidirectional LSTM (BiLSTM). Unlike a regular LSTM that reads a sequence only forward, BiLSTM reads it in both directions. That matters for emotion in EEG, because an emotional response echoes both ways through time.

Without any attention, this baseline scored 58.43%. This gave me a clear target on how hard the problem actually is.
Five Variants, One Question
The question: Does adding attention to BiLSTM make a real difference on brain signal data and which variant works best?
Here's what each one does, and what it scored on the DEAP dataset.
Here's something most introductory explanations skip: "attention" isn't one single thing. It's a family of related techniques, each designed for a different purpose. Over the years, researchers have developed several variants and choosing the right one for your problem genuinely matters. Let's go through the main ones.
1. Soft attention - 80.7%
The original and most widely used form. Soft attention computes a smooth, differentiable weighted sum over all input positions. Every word gets some weight — even if it's tiny. Because it's differentiable, the whole thing can be trained end-to-end using backpropagation, which is why it became so popular so quickly.
It worked well on the Dataset - A jump of more than 22 percentage points over baseline in one move.

2. Self Attention - 85%
Standard attention has a query from one sequence and keys/values from another. Self-attention removes that distinction — everything comes from the same sequence. Every position attends to every other position. This is how Transformers learn that "bank" near "river" means something different than "bank" near "loan."
For EEG, it means the model can discover which brain moments are structurally related to each other, without being told. Strong performer in our Dataset.

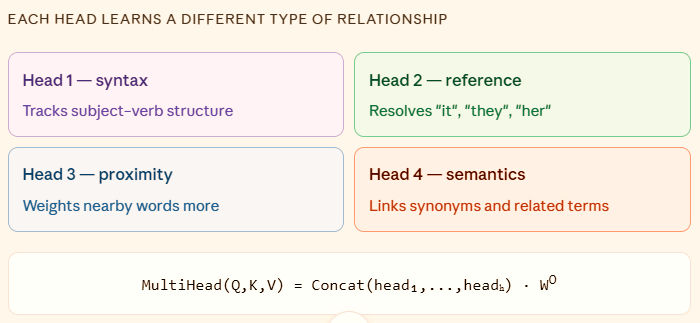
3. Multi-head attention - 53%
This variant had a complete different story . Multi-head attention runs several attention functions in parallel , each "head" looks for a different type of relationship in the data simultaneously. On paper, it's the most powerful variant in this list. It's what powers every major Transformer model today.
In practice, my hardware couldn't handle it properly. I was forced to set the batch size to 1, which broke gradient stability during training. The model never really learned. The score dropped below the no-attention baseline. This isn't a verdict on multi-head attention, It's a lesson about what happens when a powerful tool meets real-world compute limits.
4.Hard Attention - 86%
Where soft attention distributes weight smoothly across all positions, hard attention makes a binary choice: one position gets full weight (1.0), everything else gets zero. It's decisive. The catch is that this sharp selection isn't differentiable, so it requires reinforcement learning techniques to train — which makes it harder to implement. Less common in mainstream models, but on this dataset, the sharpness paid off. It topped every other variant, including the more famous ones.

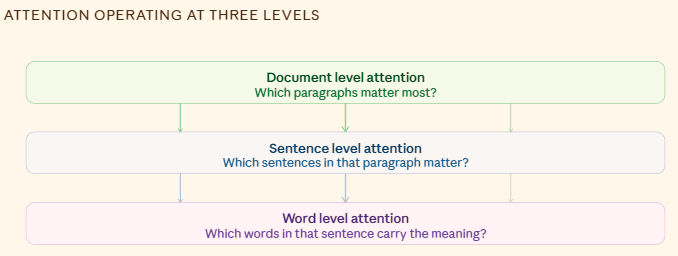
5. Multi-level attention - 85%
Most attention mechanisms operate at a single level i.e, words, or individual time steps. But real data has natural hierarchy. A document has words, sentences, and paragraphs.
An EEG recording has individual samples, short windows, and longer sessions.
Multilevel attention stacks two attention layers. The first catches fine-grained patterns, the second captures broader emotional arcs using what the first one learned. It tied self-attention at 85%, and for hierarchical biosignal data, the approach has intuitive appeal.
Where is attention actually being used today?
When I first learned about attention, every example was a translated French sentence. I kept wondering: does this actually matter beyond NLP? Turns out — very much yes.
Language & Chat
ChatGPT, Claude, Gemini -- All Transformer-based. Every long prompt you send is being processed through stacked attention layers.
Medicine & Biosignals
EEG, ECG, MRI scans. Long sequences where a few moments carry clinical meaning. Attention finds them without being told where to look.
Finance
Fraud detection and credit risk. A single odd transaction means nothing. The pattern leading up to it means everything.
Code
GitHub Copilot reads your whole codebase and understands that a function from 200 lines ago is relevant to what you're writing now. Computer Vision
Vision Transformers split images into patches and apply attention across them , learning what to focus on without pixel-level labels. Biology
AlphaFold 2 solved protein folding which is a 50-year challenge using attention to learn which amino acids shape each other's 3D structure. Nobel Prize, 2024.
What all of these share: long sequences, mostly noise, a few moments that matter. EEG emotion recognition is just one instance of that universal pattern.
Final Thoughts
When I started this research study, I thought I was searching for the "best" attention mechanism. I was very much interested in multihead Attention because it's what powers every major model today, it seemed like the obvious winner going in. It came at the last.
And hard attention, the one with the clunky reinforcement learning workarounds, the one nobody really talks about anymore came first
There is no universally best model. The effectiveness of any technique depends on the problem, the data, and the constraints around it.
Some attention mechanisms dramatically improved performance. Others didn't. One of the models I expected to perform best ended up being one of the weakest not because the mechanism is flawed, but because the conditions didn't suit it. That experience changed how I approach every project now: don't let popularity make decisions for you. Let the data do that.
Sometimes the most valuable insights come from the results you never expected. And the models that humbled you most end up teaching you the most.
