How AI Understands Our World: Through Embeddings and Vector Databases
- Pranjali Srivastava
- Aug 30
- 4 min read

Computers see data as just numbers. They don't inherently grasp context or meaning. For AI, there is no difference between “king” and “car”, but it is still able to recognize that they are not related.
This magic works because of two powerful technologies: Embeddings and Vector Databases.
This blog will break down what they are, why they're crucial for modern AI, and how they work together to power applications like semantic search and recommendation engines.
Embeddings
An embedding is a process that converts complex data—like a word, a sentence, or even an image—into a list of numbers called a vector. It is like a universal translator that turns any concept into a coordinate in a high-dimensional space.
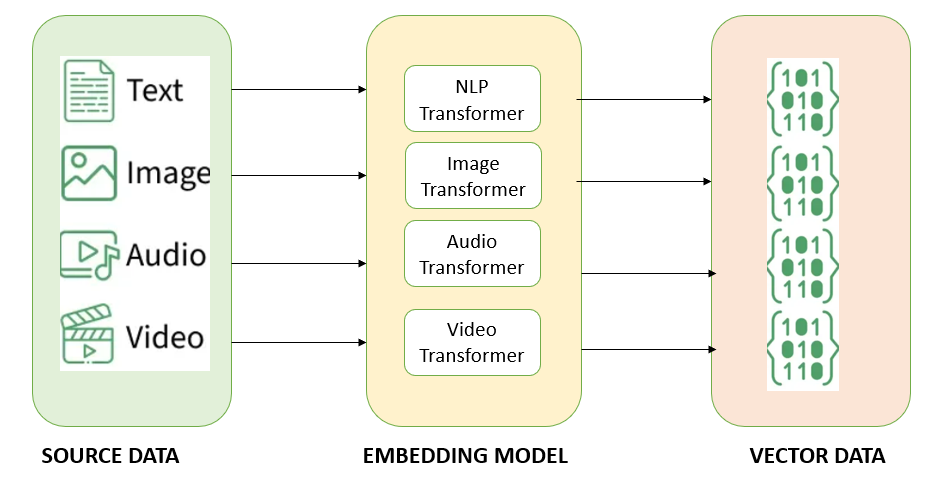
Let's understand this by a simple example. Suppose the sentence is "The cat sat on the mat."
Now this sentence will undergo through some steps -
Tokenization : The sentence breaks into tokens - ["The", "cat", "sat", "on", "the", "mat"]
Vocabulary Indexing : Based on the trained model, the tokens are indexed. So now, the tokens are indexed like [4, 1, 2, 5, 4, 3]
Embedding matrix : Based on the embedding matrix and algorithm of the embedding model, the indexed tokens are converted to corresponding vectors.
[4, 1, 2, 5, 4, 3] becomes :
"The": [0.0, 0.0, 0.0]
"cat": [0.8, -0.2, 0.5]
"sat": [0.1, 0.3, -0.1]
"on": [0.2, 0.1, -0.3]
"the": [0.0, 0.0, 0.0]
"mat": [0.7, -0.1, 0.4]
Note: "The" word has 0.0 vector because it is considered as stop words - the words which do not render any meaningful information about the sentence.
Aggregation : Now to represent the entire sentence, a single vector is needed. This is done through aggregation process. Thus, the sentence vector becomes [0.3, 0.0167, 0.0833]
This numerical representation allows a computer to "understand" relationships and context by simply measuring the distance between these vectors.
Vector Databases
Traditional databases like SQL are excellent for finding exact matches. You can ask, "Find all users whose status is 'active'," and it will return precise results. However, they are terrible at conceptual searches like, "Find articles about royal family succession." A traditional database would just look for those exact keywords.
This is where vector databases come in. They are specifically designed to do one thing exceptionally well: store and search through millions or even billions of vectors with incredible speed. For example, the vectors for "happy" and "joyful" would be very close, while the vector for "sad" would be further away, and the vector for "bicycle" would be in a completely different region.
Their core function is to perform similarity searches. When you provide a vector (representing your query), the database doesn't look for an exact match. Instead, it finds the "nearest neighbors"—the vectors in its index that are mathematically closest to your query vector. It does this using highly efficient algorithms, most commonly a technique called Approximate Nearest Neighbor (ANN), which prioritizes speed for real-time applications.
How They Work Together?
Embeddings and vector databases are a powerful duo. They are the foundation of a technique called Retrieval-Augmented Generation (RAG), which is used to build smart Q&A bots and other knowledge-based AI systems.
Here’s a step-by-step example of how a RAG system works:
Step 1: Storing Knowledge (Ingestion)
First, you take your knowledge base e.g., all your company's internal documents, FAQs, and break it down into smaller, manageable chunks of text.
Each chunk is fed into an embedding model (like models from OpenAI, Cohere, or open-source alternatives).
The model converts each chunk into a vector.
All these vectors are stored in a vector database (like Pinecone, Milvus, or Chroma).
Step 2: Asking a Question (Querying)
Now, a user asks a question, such as, "How do I reset my password?"
The user's question is converted into a vector using the same embedding model.
This new vector is used to search the vector database.
The database instantly returns the top few text chunks whose vectors are most similar to the question's vector. These are the documents most relevant to the user's query.
Step 3: Generating an Answer (Generation)
Finally, the retrieved text chunks are passed to a Large Language Model (LLM) along with the original question. The LLM is given a prompt like: "Using the following context, answer the user's question. Context: [retrieved text chunks]. Question: How do I reset my password?"
The LLM then generates a precise, contextually-aware answer based only on the relevant information you provided, rather than relying on its generalized, and possibly outdated, knowledge.

Here is a simplified code snippet showing the core idea of creating embeddings and finding similarity.
from sentence_transformers import SentenceTransformer, util
import torch
# 1. Load a pre-trained embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# 2. Your knowledge base (documents)
documents = [
"To reset your password, go to the login page and click 'Forgot Password'.",
"Our company was founded in 2005.",
"You can find our return policy on the checkout page."
]
# 3. Convert documents to vectors (embeddings)
doc_embeddings = model.encode(documents, convert_to_tensor=True)
# 4. A user asks a question
user_query = "How do I change my login credentials?"
# 5. Convert the query to a vector
query_embedding = model.encode(user_query, convert_to_tensor=True)
# 6. Compute similarity scores between the query and all documents
# In a real application, a vector database does this search efficiently
cosine_scores = util.cos_sim(query_embedding, doc_embeddings)
# Find the document with the highest similarity
best_match_index = torch.argmax(cosine_scores)
print(f"User Query: {user_query}")
print(f"Most Relevant Document: '{documents[best_match_index]}'")
Conclusion
Embeddings and vector databases are fundamental building blocks for the next generation of AI applications. Embeddings translate our messy, contextual world into the clean, numerical language of vectors. Vector databases act as the super-fast memory and search engine for that language. Together, they enable AI to understand meaning, find relevant information, and provide accurate, context-aware answers.


