Clean them before using them - Maternal Health Project.
- knncourse
- Sep 2
- 4 min read
Data cleaning impacts data analysis by improving the quality of the underlying data and hence the trustworthiness of study results. Let us dive deep into the data cleaning process of the Demographics of the Obeservations database of the Maternal Health Project.
The Observations dataset is a rich collection of data from a cohort study conducted in Porto Alegre, Brazil. It includes 211 pregnant women with detailed ultrasound measurements of maternal abdominal fat alongside nutritional, demographic, lab and pregnancy outcome variables. This dataset contains 116 variable capturing baseline anthropometric data, ultrasound fat measurements at periumbilical and epigastric sties, maternal blood pressure, blood glucose levels, pregnancy complications, and newborn health indication. Given the complexity and volume of data collected, rigorous data cleaning is essential to ensure accuracy and usability for subsequent analyses.
Data cleaning steps involve handling missing values, verifying consistency across repeated measurements, correcting or flagging improbable values, standardizing categorical codes, and integrating retrospective clinical outcome data from hospital records. These steps help prepare a reliable and high quality dataset that enables robust research on the relationship between maternal abdominal fat and gestational outcomes such as gestational diabetes, hypertension, and birth complications.
Unit conversions and variable harmonization across columns in the dataset are essential steps to ensure consistency, comparability and accuracy for analysis. Several strategies have to be followed. First the measurement units have to be standardized. Variables such as weight, height, and fat thickness, which might have been recorded in different units, have to be converted into uniform units. Well defined conversion factors maintain the consistency of the meaning and scale of each variable. Next, the harmonized variables can be derived. Variables like BMI have to be recalculated from cleaned and standardized weight and height data to create harmonized derivative variables that accurately reflect the corresponding anthropometric status.
The Demographics includes the following parameters - Case_id, age, color_ethnicity, height_at_inclusion, prepregnant_weight, prepregnant_bmi, bmi_according_who, maternal_weight_at_inclusion, current_bmi, current_bmi_according_who.
We have three bmi values - bmi_according_who, current_bmi_according_who and current_bmi.
bmi_according_who is associated with the prepregnant_weight and prepregnant_bmi.
current_bmi refers to the BMI measured at the time of inclusion and current_bmi_according_who refers to the ideal range of BMI according to WHO.
Let's get into the cleaning steps.
a. prepregnant_weight
After filtering this colum, we have two blank fields and 10 no_answer fields. As the maternal weight at first trimester is the closest in time frame to the prepregnant weight, these values can be used to update the blanks and no_answers.

The prepregnant_weight column blanks and no_answers can be replaced with the corresponding current_maternal_weight_1st_Tri values. The three blank spaces of current_maternal_weight_1st_Tri can be replaced with average of this column which is 72.30.
b. prepregnant_bmi
After filtering this column, there are 11 blanks fields and 1 not_applicable field. With the updated prepregnant weight values and the height at inclusion values, the prepregnant BMI can be calculated.

The prepregnant_bmi column blanks and not_applicable can be filled by using the already cleaned prepregnant_weight column values and the height_at_inclusion values in the BMI formula.
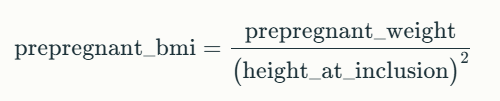
Before this step, the blank value of the height_at_inclusion column has to be filled. This can be found by using the below re-arranged BMI formula.
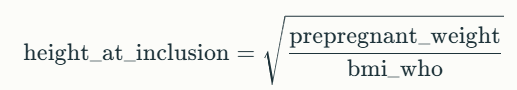
c. maternal_weight_at_inclusion

There are two blanks in this column. One of the blanks can be calculated using the height_at_inclusion and current_bmi values. We can use the below BMI formula

The other blank value of maternal_weight_at_inclusion can be filled using the current_maternal_weight_at_inclusion value as it can be inferred that the inclusion was in the first trimester.
d. bmi_according_who

As this value is associated with the prepregnant phase, we can use the already cleaned values of prepregnant_weight and prepregnant_bmi columns.
e. current_bmi
As mentioned above, current_bmi is related to the bmi value at the time of inclusion.

As we have the 1st trimester weight, we can use this along with the cleaned and filled value of the height_at_inclusion to calculate the current_bmi.

f. current_bmi_according_who

We can use the cleaned data of current_bmi to fill the current_bmi_according_who blank field. As the current_bmi_according_who values are in 0,1,2,3 values, we can use the below BMI chart to convert the decimal values of current_bmi.

g. Case_id
This column had no blank fields.
h. age column
This column had no blank fields.
i. color_ethnicity
There were 3 blank fields found. As no other data provides information to fill these fields, these were kept as not_available.
Thorough data consistency checks, corrections of implausible values, handling of missing data, and recalculation of derived indices like BMI ensures that the dataset maintains scientific integrity and minimizes bias from measurement or recording errors. These steps lead to a strong foundation for subsequent analyses focusing on the predictive value of maternal abdominal fat and nutritional status on gestational complications and neonatal outcomes.
A deep understanding of what the columns convey, considering their context, time of recording and datatypes help a great deal in using them across the table for data cleaning and filling. importantly, once a column had been cleaned, its filled in values can be used for further columns. Remember to keep use the updated columns for every next step of data cleaning. Data cleaning involves handling missing values, verifying consistency across repeated measurements, correcting or flagging improbable values, standardizing categorical codes, and integrating retrospect clinical outcome data from hospital records.


